Memories Atlas. pt.1
AI Generative Latent Video /
2021
Memories Atlas is a series of artwork that explores how machines interpret and re-create private/collective memories.
Waiheke is a series of prints of transparency film selected from a trained video from a GANs model. The original footage is the artist's family video recording of playing on the seaside. Each frame from the original video is intercepted as the dataset used in machine learning. Past moments in time are re-lived through the eyes of an artificial intelligence model, reconstructs and reinterprets the original everyday fragments through training. It attempts to explore how memories are displayed artificially. How does artificial intelligence reconstruct the memory fragments of the past through its observation?
AI Generative Latent Video /
Transparency films
2021Memories Atlas is a series of artwork that explores how machines interpret and re-create private/collective memories.
Waiheke is a series of prints of transparency film selected from a trained video from a GANs model. The original footage is the artist's family video recording of playing on the seaside. Each frame from the original video is intercepted as the dataset used in machine learning. Past moments in time are re-lived through the eyes of an artificial intelligence model, reconstructs and reinterprets the original everyday fragments through training. It attempts to explore how memories are displayed artificially. How does artificial intelligence reconstruct the memory fragments of the past through its observation?





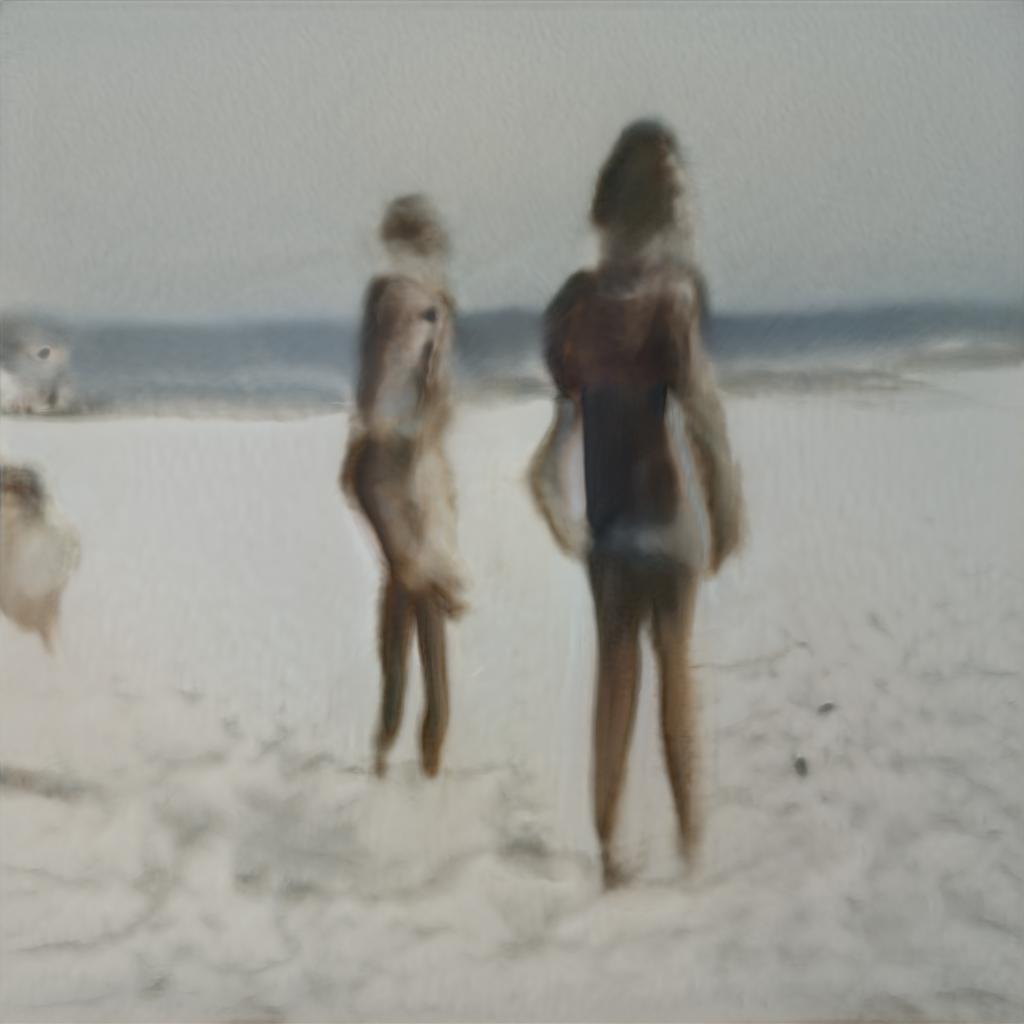


Look and Read
Three-channel video Installation,
2022
Look and Read is a 3-channel video consisting of a series of image datasets selected from famous conceptual and abstract artworks from contemporary art history. Each artwork image has one or more colour-coded rectangular boxes on it. The rectangular box indicates that the machine learning algorithm identifies the artwork's image element, and the identified noun appears above the box.
These visual compositions of images with boxes and text look like the YOLO model, which is widely used for AI object recognition and object detection. The algorithm model is typically used for object detection in technologies such as autonomous driving. By learning, human labelling and classifying large batches of image information, the machine can recognize objects within the frame with the help of the YOLO algorithm as it learns to classify large batches of information.
However, a reversal of this artwork is that it is not the YOLO algorithm that presents the recognition results, but the words are named by three children aged 7-9. These words are their first response when they look at the artwork. I asked them to view works from contemporary art history, and they responded to the artworks after naming each one with only a noun. It is worth noting that these children had not seen these works.
Look and Read seeks to expose, in a counterfactual way, the possible human intervention in training today's artificial intelligence in datasets. In today's digital age, collecting data on a large scale requires a human being to classify the data. AI algorithms cannot understand datasets' potential complexity and subjectivity. Seemingly innocuous and anonymised data messages are often laced with highly personalised messages. These messages can lead to social issues of bias and subjectivity in implementing AI technologies, raising questions about AI data subjects.
The work also attempts to echo John Searle's The Chinese Room argument. This thought experiment is used to counter the idea that computers and other artificial intelligence can think. Unlike the Chinese Room scenario, the three children respond to the artwork from their imagination and subconscious. They may not understand the artwork's meaning, but their imagination and subconscious can give them a unique response to the artwork.
A headphone will be attached to the bottom of each of the video, and inside the headphone plays a recording of the children's words.
Three-channel video Installation,
with headphones
2022Look and Read is a 3-channel video consisting of a series of image datasets selected from famous conceptual and abstract artworks from contemporary art history. Each artwork image has one or more colour-coded rectangular boxes on it. The rectangular box indicates that the machine learning algorithm identifies the artwork's image element, and the identified noun appears above the box.
These visual compositions of images with boxes and text look like the YOLO model, which is widely used for AI object recognition and object detection. The algorithm model is typically used for object detection in technologies such as autonomous driving. By learning, human labelling and classifying large batches of image information, the machine can recognize objects within the frame with the help of the YOLO algorithm as it learns to classify large batches of information.
However, a reversal of this artwork is that it is not the YOLO algorithm that presents the recognition results, but the words are named by three children aged 7-9. These words are their first response when they look at the artwork. I asked them to view works from contemporary art history, and they responded to the artworks after naming each one with only a noun. It is worth noting that these children had not seen these works.
Look and Read seeks to expose, in a counterfactual way, the possible human intervention in training today's artificial intelligence in datasets. In today's digital age, collecting data on a large scale requires a human being to classify the data. AI algorithms cannot understand datasets' potential complexity and subjectivity. Seemingly innocuous and anonymised data messages are often laced with highly personalised messages. These messages can lead to social issues of bias and subjectivity in implementing AI technologies, raising questions about AI data subjects.
The work also attempts to echo John Searle's The Chinese Room argument. This thought experiment is used to counter the idea that computers and other artificial intelligence can think. Unlike the Chinese Room scenario, the three children respond to the artwork from their imagination and subconscious. They may not understand the artwork's meaning, but their imagination and subconscious can give them a unique response to the artwork.
A headphone will be attached to the bottom of each of the video, and inside the headphone plays a recording of the children's words.




Imaginary Sunset
AI Generative Video
Installation
2021
Imaginary Sunset is an AI-generated video that investigates how technology interprets collective memory experience. The machine learning model generates a set of fictional landscape pictures using a custom dataset of sunset photographs taken by individuals around the globe on social media platforms in 2020. It attempts to transform the real, existing collective memory photographs into fictional images.
It explored how artificial intelligence is being used to interrogate the duality between reality and fake and is supposed to recreate memories about the pandemic lockdown from a machinery perspective. The sunset landscape is a typical and commonplace photographic subject. Even so, in the midst of the worldwide pandemic, it takes on a significance that cuts over cultural and political boundaries, as though as a symbol of humanity observing the times.
AI Generative Video
Installation
2021
Imaginary Sunset is an AI-generated video that investigates how technology interprets collective memory experience. The machine learning model generates a set of fictional landscape pictures using a custom dataset of sunset photographs taken by individuals around the globe on social media platforms in 2020. It attempts to transform the real, existing collective memory photographs into fictional images.
It explored how artificial intelligence is being used to interrogate the duality between reality and fake and is supposed to recreate memories about the pandemic lockdown from a machinery perspective. The sunset landscape is a typical and commonplace photographic subject. Even so, in the midst of the worldwide pandemic, it takes on a significance that cuts over cultural and political boundaries, as though as a symbol of humanity observing the times.






Them
AI - generated images with Film Slides
2023
This work consists of a series of positive film slides placed on a slide projector. The film that loops on the slide show is a series of fictional portraits of people. The photographs were synthesised by artificial intelligence, with the artist organising his family albums before curating and selecting the pictures to form an original data set. The artist then used different AI models to process them, creating images that appear to be based on the artist's memories but which are nonetheless ambiguous, difficult to recognize.
Them illustrates how memory is mediated and transformed through technology. In order to explore how family photographs are based on personal memories, our individual memory can here be interpreted and reconstructed through the eyes of a machine. Family portraits are the most common and mundane photographic subject matter. The artist collected his datasets from a group of family pictures captured using a film camera, which were then processed digitally by machine learning and recreated using a text-to-image conversion process, turning these familiar family portraits into fictional figures. The portraits of ordinary family members are thus turned into unrecognisable digital figures and then printed back into the medium of analog film. The past private memory has been estranged through technology. In this way, the work explores the reconstruction of human memory by machines, and imagines the potential relationship between photography and artificial intelligence.
AI - generated images with Film Slides
2023
This work consists of a series of positive film slides placed on a slide projector. The film that loops on the slide show is a series of fictional portraits of people. The photographs were synthesised by artificial intelligence, with the artist organising his family albums before curating and selecting the pictures to form an original data set. The artist then used different AI models to process them, creating images that appear to be based on the artist's memories but which are nonetheless ambiguous, difficult to recognize.
Them illustrates how memory is mediated and transformed through technology. In order to explore how family photographs are based on personal memories, our individual memory can here be interpreted and reconstructed through the eyes of a machine. Family portraits are the most common and mundane photographic subject matter. The artist collected his datasets from a group of family pictures captured using a film camera, which were then processed digitally by machine learning and recreated using a text-to-image conversion process, turning these familiar family portraits into fictional figures. The portraits of ordinary family members are thus turned into unrecognisable digital figures and then printed back into the medium of analog film. The past private memory has been estranged through technology. In this way, the work explores the reconstruction of human memory by machines, and imagines the potential relationship between photography and artificial intelligence.




Cinema Meowdiso
AI-generated Films, Generative Film System
2024
Collaboration with Xiaoyun Zhong
“Cinema Meowdiso” is a system that ingeniously combines everyday pet life with artificial intelligence technology, transforming ordinary pet videos into imaginative short films. This system explores the potential of non-human entities as narrative subjects while investigating how AI can autonomously create cinematic imagery from a cat's perspective under minimal human guidance.
At the heart of the project is an automated visual storytelling system based on a pet's point of view. It aims to create a fictional narrative experience that resonates and interacts with real-life imagery in intriguing ways.
Our protagonist and 'cinematographer' is a cat named Whisker. Equipped with a portable camera, Whisker captures precious moments of its daily home life. Our AI system then intelligently filters and processes these raw images, transforming them into scene elements of various film genres. We've carefully selected science fiction, detective, gangster, kung fu, western, and horror as reference bases for AI learning and content generation.
Daily, the system generates and pushes a random genre short film to pet owners. This element of surprise adds to the viewing experience, as owners never know what style of 'cat blockbuster' they'll receive.
The name 'Cinema Meowdiso' pays homage to the classic film 'Cinema Paradiso'. While in 'Cinema Paradiso', films become a reflection and solace for the protagonist's life, in 'Cinema Meowdiso', we assign this role to our cat. This creates a unique intertextuality: the cat's real-life experiences intertwine with AI-generated film narratives, forming an intriguing and profound dialogue.
It not only explores the possibilities of pets and AI as co-creators but also challenges our traditional understanding of narrative subjects and creative processes. It further prompts reflection on human-machine collaboration, non-human perspectives, and the boundaries between fiction and reality.
Credits:
Nolan Huang Xuanyang (Director) Xiaoyun Zhong (Technical Development)
Cengceng (The Cat)
Wei Huang
Kedouh (Graphics Design)
Support by
Computational Media and Arts Lab, Hong Kong University of Science and Technology (Guangzhou)
AI-generated Films, Generative Film System
2024
Collaboration with Xiaoyun Zhong
“Cinema Meowdiso” is a system that ingeniously combines everyday pet life with artificial intelligence technology, transforming ordinary pet videos into imaginative short films. This system explores the potential of non-human entities as narrative subjects while investigating how AI can autonomously create cinematic imagery from a cat's perspective under minimal human guidance.
At the heart of the project is an automated visual storytelling system based on a pet's point of view. It aims to create a fictional narrative experience that resonates and interacts with real-life imagery in intriguing ways.
Our protagonist and 'cinematographer' is a cat named Whisker. Equipped with a portable camera, Whisker captures precious moments of its daily home life. Our AI system then intelligently filters and processes these raw images, transforming them into scene elements of various film genres. We've carefully selected science fiction, detective, gangster, kung fu, western, and horror as reference bases for AI learning and content generation.
Daily, the system generates and pushes a random genre short film to pet owners. This element of surprise adds to the viewing experience, as owners never know what style of 'cat blockbuster' they'll receive.
The name 'Cinema Meowdiso' pays homage to the classic film 'Cinema Paradiso'. While in 'Cinema Paradiso', films become a reflection and solace for the protagonist's life, in 'Cinema Meowdiso', we assign this role to our cat. This creates a unique intertextuality: the cat's real-life experiences intertwine with AI-generated film narratives, forming an intriguing and profound dialogue.
It not only explores the possibilities of pets and AI as co-creators but also challenges our traditional understanding of narrative subjects and creative processes. It further prompts reflection on human-machine collaboration, non-human perspectives, and the boundaries between fiction and reality.
Credits:
Nolan Huang Xuanyang (Director) Xiaoyun Zhong (Technical Development)
Cengceng (The Cat)
Wei Huang
Kedouh (Graphics Design)
Support by
Computational Media and Arts Lab, Hong Kong University of Science and Technology (Guangzhou)





